One core per compute unit что это
one-core-per-bit circuit
Большой англо-русский и русско-английский словарь . 2001 .
Смотреть что такое «one-core-per-bit circuit» в других словарях:
Bit — This article is about the unit of information. For other uses, see Bit (disambiguation). Fundamental units of information bit (binary) nat (base e) ban (decimal) qubit (quantum) This box … Wikipedia
Multi-core processor — Diagram of a generic dual core processor, with CPU local level 1 caches, and a shared, on die level 2 cache … Wikipedia
Magnetic-core memory — A 32 x 32 core memory plane storing 1024 bits of data. Computer memory types Volatile RAM DRAM (e.g., DDR SDRAM) SRA … Wikipedia
Multi-core — A multi core processor (or chip level multiprocessor, CMP) combines two or more independent cores into a single package composed of a single integrated circuit (IC), called a die, or more dies packaged together. The individual core is normally a… … Wikipedia
Magnetic core memory — Magnetic core memory, or ferrite core memory, is an early form of random access computer memory. It uses small magnetic ceramic rings, the cores , through which wires are threaded to store information via the polarity of the magnetic field they… … Wikipedia
Drill bit — For the fictional character, see Drill Bit (Transformers). For the cancelled skyscraper nicknamed Drill bit, see Chicago Spire. For the types used in drilling wells, see Well drilling. From top to bottom: Spade, lip and spur (brad point), masonry … Wikipedia
Integrated circuit — Silicon chip redirects here. For the electronics magazine, see Silicon Chip. Integrated circuit from an EPROM memory microchip showing the memory blocks, the supporting circuitry and the fine silver wires which connect the integrated circuit die… … Wikipedia
computer — computerlike, adj. /keuhm pyooh teuhr/, n. 1. Also called processor. an electronic device designed to accept data, perform prescribed mathematical and logical operations at high speed, and display the results of these operations. Cf. analog… … Universalium
Central processing unit — CPU redirects here. For other uses, see CPU (disambiguation). An Intel 80486DX2 CPU from above An Intel 80486DX2 from below … Wikipedia
Computers and Information Systems — ▪ 2009 Introduction Smartphone: The New Computer. The market for the smartphone in reality a handheld computer for Web browsing, e mail, music, and video that was integrated with a cellular telephone continued to grow in 2008. According to… … Universalium
PIC microcontroller — PIC microcontrollers in DIP and QFN packages … Wikipedia
One core per compute unit что это
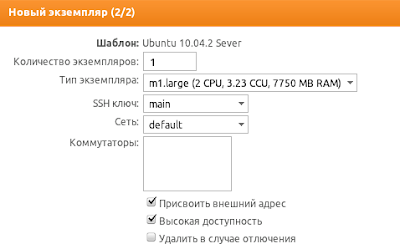
Когда вы запускаете виртуальную машину в нашем облаке, вам предлагается выбрать ее тип, описание которого выглядит следующим образом: m1.large (2 CPU, 3.23 CCU, 7750 MB RAM). С CPU и RAM все понятно — это, соответственно, количество ядер и размер оперативной памяти в виртуальной машине. Но что же такое CCU?
Наше облако состоит из большого количества машин. И эти машины не обязательно имеют одинаковую производительность: у них могут быть разные типы процессоров, разное количество оперативной памяти и т. п. Но когда вы запускаете виртуальную машину, мы должны гарантировать, что во время работы она получит не меньше вычислительных ресурсов, чем другие машины такого же типа вне зависимости от того, на какой физической машине она была запущена.
В результате возникает необходимость в единицах измерения производительности виртуальных машин. Такой единицей у нас является CCU (CROC Compute Unit). Для простоты понимания CCU можно сравнить с мегагерцами — по крайней мере, лет 10 назад производительность процессоров можно было приблизительно оценить, сравнив их тактовые частоты.
Каким образом мы определяем, сколько Compute Unit’ов в одном физическом ядре? На измеряемой машине мы запускаем тесты производительности и на основе результатов тестирования и эталонных значений вычисляем CCU данной машины. Чему равен 1 CCU? Для удобства мы выбрали 1 CROC Compute Unit таким, чтобы он был приблизительно равен 1 EC2 Compute Unit (http://aws.amazon.com/ec2/instance-types/).
Каким же образом происходит выделение ресурсов для виртуальных машин на реальных машинах? Очень просто. К примеру, у нас есть физическая машина с 2 ядрами по 2 CCU каждое. На этой машине мы можем запустить:
- 1 машину с 2 CPU x 2 CCU;
- 2 машины с 4 CPU x 0.5 CCU;
- 1 машину с 1 CPU x 1 CCU и 3 машины с 2 CPU x 0.5 CCU;
и т. д.
Но, к примеру, виртуальную машину с 1 CPU x 4 CCU на данной физической мы запустить уже не сможем, т. к. ядра виртуальных машин должны размещаться на физических ядрах таким образом, чтобы не пересекать границы физических ядер.
В реальности все немного сложнее, т. к. часть процессорного времени и оперативной памяти резервируется для системных процессов, но в целом принцип именно такой.
Если на одном физическом ядре работают, к примеру, две машины (1 CCU и 2 ССU), то гипервизор распределяет процессорное время между ними таким образом, чтобы второй виртуальной машине выделялось в два раза больше процессорного времени, чем первой.
В результате, отвечая на поставленный вопрос, вышеупомянутое описание типа «m1.large (2 CPU, 3.23 CCU, 7750 MB RAM)» следует понимать как: виртуальная машина с 2 ядрами и 7750 MB оперативной памяти, производительность каждого ядра — 3.23 CCU, суммарная производительность виртуальной машины — 2 * 3.23 CCU = 6.46 CCU.
Утилита CUINFO позволяет разблокировать блоки Compute Units GPU Fiji, Hawaii и Tonga
Вновь и вновь в Интернете появляется информация об утилитах и специализированных версиях BIOS, которые позволяют разблокировать архитектурные блоки GPU. На этот раз новость касается некоторых GPU от AMD.
AMD и NVIDIA выбирают разные аппаратные конфигурации GPU для своих видеокарт. Благодаря этому они могут использовать частично дефектные GPU, отключив сбойные блоки. Конечно, есть возможность специально отключать и хорошие блоки, чтобы дифференцировать чипы. Речь сегодня пойдет об утилите CUINFO от пользователя tx12 с форума Overclock.net. Она показывает, сколько именно блоков Compute Unit отключено в GPU. Некоторые блоки могут быть просто деактивированными, другие являются сбойными, третьи аппаратно отключены лазерной резкой. И утилита как раз позволяет узнать, какие блоки Compute Units можно теоретически активировать.
Утилита потенциально должна работать со всеми GPU AMD «Fiji», «Hawaii» и «Tonga». Скорее всего, будут корректно определяться и все новые архитектуры GCN. Утилита тестировалась на GPU «Fiji» в новых видеокартах Fury, а именно Radeon R9 Fury X (тест и обзор) и Radeon R9 Fury (тест видеокарт ASUS и Sapphire). Видеокарты GPU «Hawaii» относятся к предыдущему поколению – поддерживаются Radeon R9 290X и Radeon R9 290. Что касается новой редакции с кодовым названием «Grenada» в виде Radeon R9 390X (тест и обзор), то утилиту потенциально использовать можно, но сможет ли она активировать CU – пока неизвестно. Видеокарты Radeon R9 285 (тест и обзор) и Radeon R9 380 (тест и обзор) опираются на упомянутый GPU «Tonga» – с ними утилита тоже может обращаться к конфигурации CU.
Разработчик CUINFO в качестве примера взял Sapphire Radeon R9 Fury Tri-X, утилита выдала следующие значения:
Adapters detected: 1
Card #1 PCI ID: 1002:7300 — 174B:E329
DevID [7300] Rev [CB] (0), memory config: 0x00000000 (unused)
Fiji-class chip with 16 compute units per Shader Engine
SE1 hw/sw: 00030000 / 00000000 [. xx]
SE2 hw/sw: 02400000 / 00000000 [. x..x. ]
SE3 hw/sw: 90000000 / 00000000 [x..x. ]
SE4 hw/sw: 00090000 / 00000000 [. x..x]
56 of 64 CUs are active. HW locks: 8 (R/W) / SW locks: 0 (R/W).
8 CU’s are disabled by HW lock, override is possible at your own risk.
То есть активны 56 из 64 доступных блоков Compute Units. То есть каждый восьмой CU заблокирован аппаратным способом, активация невозможна или очень трудоемка. Обратите внимание, что почти все заблокированные CU находятся в разных столбцах. Возможны конфигурации, когда из заблокированных CU формируется целый столбец. Ниже приведен вариант конфигурации, когда один столбец полностью заполнен.
SE1 hw/sw: 00030000 / 00000000 [. x.x]
SE2 hw/sw: 02400000 / 00000000 [. xx]
SE3 hw/sw: 90000000 / 00000000 [. x.x]
SE4 hw/sw: 00090000 / 00000000 [. xx]
TX12, разработчик CUINFO, описывает ситуацию так:
«Как правило, вам следует пытаться разблокировать некоторые ядра ТОЛЬКО если не менее одного из двух самых правых столбцов заполнено «x». На примере выше только самый правый столбец (#1) заполнен «x», а второй столбец (#2) уже не заполнен целиком. Если ни один из двух правых столбцов не заполнен целиком «x», то вам, скорее всего, не повезло. И думать о разблокировке не стоит. Или пробовать все ROM и надеяться на удачу (не рекомендуется)».
Но дело, конечно, не заканчивается информацией об отключенных CU. TX12 предлагает скрипт, создающий три разные версии BIOS. В зависимости от позиции и числа заполненных столбцов CPU, следует использовать свою версию BIOS. Все детали подобно описаны в руководстве на английском. Важно не забыть сделать резервную копию оригинальной версии BIOS.
Введение в GPU-вычисления – CUDA/OpenCL
Введение в GPU-вычисления
Видеокарты – это не только показатель фпс в новейших играх, это еще и первобытная мощь параллельных вычислений, оставляющая позади самые могучие процессоры. В видеокартах таится множество простых процессоров, умеющих лихо перемалывать большие объемы данных. GPU-программирование – это та отрасль параллельных вычислений где все еще никак не устаканятся единые стандарты – что затрудняет использование простаивающих мощностей.
В этой заметке собрана информация которая поможет понять общие принципы GPU-программирования.
Введение в архитектуру GPU
Разделяют два вида устройств – то которое управляет общей логикой – host, и то которое умеет быстро выполнить некоторый набор инструкций над большим объемом данных – device. 
В роли хоста обычно выступает центральный процессор (CPU – например i5/i7).
В роли вычислительного устройства – видеокарта (GPU – GTX690/HD7970). Видеокарта содержит Compute Units – процессорные ядра. Неразбериху вводят и производители NVidia называет свои Streaming Multiprocessor unit или SMX , а
ATI – SIMD Engine или Vector Processor. В современных игровых видеокартах – их 8-32.
Процессорные ядра могут исполнять несколько потоков за счет того, что в каждом содержится несколько (8-16) потоковых процессоров (Stream Cores или Stream Processor). Для карт NVidia – вычисления производятся непосредственно на потоковых процессорах, но ATI ввели еще один уровень абстракции – каждый потоковый процессор, состоит из processing elements – PE (иногда называемых ALU – arithmetic and logic unit) – и вычисления происходят на них.
Необходимо явно подчеркнуть что конкретная архитектура (число всяческих процессоров) и вычислительные возможности варьируются от модели к модели – что несколько влияет на универсальность и простоту кода для видеокарт от обоих производителей.
Для CUDA-устройств от NVidia это sm10, sm20, sm30 и т.д. Для OpenCL видеокарт от ATI/NVidia определяющее значение имеет версия OpenCL реализованная в драйверах от производителя 1.0, 1.1, 1.2 и поддержка особенностей на уровне железа. Да, вы вполне можете столкнуться с ситуацией когда на уровне железа какие-то функции просто не реализованы (как например локальная память на амд-ешных видеокарт линейки HD4800). Да, вы вполне можете столкнуться с ситуацией когда какие-то функции не реализованы в драйверах (на момент написания – выполнение нескольких ядер на видео-картах от NVidia с помощью OpenCL).
Программирование для GPU

Программы пишутся на расширении языка Си от NVidia/OpenCL и компилируются с помощью специальных компиляторов входящих в SDK. У каждого производителя разумеется свой. Есть два варианта сборки – под целевую платформу – когда явно указывается на каком железе будет исполнятся код или в некоторый промежуточный код, который при запуске на целевом железе будет преобразован драйвером в набор конкретных инструкций для используемой архитектуры (с поправкой на вычислительные возможности железа).
 Выполняемая на GPU программа называется ядром – kernel – что для CUDA что для OpenCL это и будет тот набор инструкций которые применяются ко всем данным. Функция одна, а данные на которых она выполняется – разные – принцип SIMD.
Выполняемая на GPU программа называется ядром – kernel – что для CUDA что для OpenCL это и будет тот набор инструкций которые применяются ко всем данным. Функция одна, а данные на которых она выполняется – разные – принцип SIMD.
Важно понимать что память хоста (оперативная) и видеокарты – это две разные вещи и перед выполнением ядра на видеокарте, данные необходимо загрузить из оперативной памяти хоста в память видеокарты. Для того чтобы получить результат – необходимо выполнить обратный процесс. Здесь есть ограничения по скорости PCI-шины – потому чем реже данные будут гулять между видеокартой и хостом – тем лучше.
Драйвер CUDA/OpenCL разбивает входные данные на множество частей (потоки выполнения объединенные в блоки) и назначает для выполнения на каждый потоковый процессор. Программист может и должен указывать драйверу как максимально эффективно задействовать существующие вычислительные ресурсы, задавая размеры блоков и число потоков в них. Разумеется, максимально допустимые значения варьируются от устройства к устройству. Хорошая практика – перед выполнением запросить параметры железа, на котором будет выполняться ядро и на их основании вычислить оптимальные размеры блоков.
Схематично, распределение задач на GPU происходит так:

Выполнение программы на GPU
work-item (OpenCL) или thread (CUDA) – ядро и набор данных, выполняется на Stream Processor (Processing Element в случае ATI устройств).
work group (OpenCL) или thread block (CUDA) выполняется на Multi Processor (SIMD Engine)
Grid (набор блоков такое понятие есть только у НВидиа) = выполняется на целом устройстве – GPU. Для выполнения на GPU все потоки объединяются в варпы (warp – CUDA) или вейффронты (wavefront – OpenCL) – пул потоков, назначенных на выполнение на одном отдельном мультипроцессоре. То есть если число блоков или рабочих групп оказалось больше чем число мултипроцессоров – фактически, в каждый момент времени выполняется группа (или группы) объединенные в варп – все остальные ожидают своей очереди.
Одно ядро может выполняться на нескольких GPU устройствах (как для CUDA так и для OpenCL, как для карточек ATI так и для NVidia).
Одно GPU-устройство может одновременно выполнять несколько ядер (как для CUDA так и для OpenCL, для NVidia – начиная с архитектуры 20 и выше). Ссылки по данным вопросам см. в конце статьи.
Модель памяти OpenCL (в скобках – терминология CUDA)

Здесь главное запомнить про время доступа к каждому виду памяти. Самый медленный это глобальная память – у современных видекарт ее аж до 6 Гб. Далее по скорости идет разделяемая память (shared – CUDA, local – OpenCL) – общая для всех потоков в блоке (thread block – CUDA, work-group – OpenCL) – однако ее всегда мало – 32-48 Кб для мультипроцессора. Самой быстрой является локальная память за счет использования регистров и кеширования, но надо понимать что все что не уместилось в кеширегистры – будет хранится в глобальной памяти со всеми вытекающими.
Паттерны параллельного программирования для GPU
1. Map

Map – GPU parallel pattern
Тут все просто – берем входной массив данных и к каждому элементу применяем некий оператор – ядро – никак не затрагивающий остальные элементы – т.е. читаем и пишем в определенные ячейки памяти.
Отношение – как один к одному (one-to-one).
пример – перемножение матриц, оператор инкремента или декремента примененный к каждому элементу матрицы и т.п.
2. Scatter

Scatter – GPU parallel pattern
Для каждого элемента входного массива мы вычисляем позицию в выходном массиве, на которое он окажет влияние (путем применения соответствующего оператора).
Отношение – как один ко многим (one-to-many).
3. Transpose
![]()
![]()
Transpose – GPU parallel pattern
Данный паттерн можно рассматривать как частный случай паттерна scatter.
Используется для оптимизации вычислений – перераспределяя элементы в памяти можно достичь значительного повышения производительности.
4. Gather

Gather – GPU parallel pattern
Является обратным к паттерну Scatter – для каждого элемента в выходном массиве мы вычисляем индексы элементов из входного массива, которые окажут на него влияние:
Отношение – несколько к одному (many-to-one).
5. Stencil

Stencil – GPU parallel pattern
Данный паттерн можно рассматривать как частный случай паттерна gather. Здесь для получения значения в каждой ячейке выходного массива используется определенный шаблон для вычисления всех элементов входного массива, которые повлияют на финальное значение. Всевозможные фильтры построены именно по этому принципу.
Отношение несколько к одному (several-to-one)
Пример: фильтр Гауссиана.
6. Reduce

Reduce – GPU parallel pattern
Отношение все к одному (All-to-one)
Пример – вычисление суммы или максимума в массиве.
7. Scan/ Sort
При вычислении значения в каждой ячейке выходного массива необходимо учитывать значения каждого элемента входного. Существует две основные реализации – Hillis and Steele и Blelloch.
out[i] = F[i] = operator(F[i-1],in[i])
Отношение все ко всем (all-to-all).
Примеры – сортировка данных.
Полезные ссылки
Введение в CUDA:
Введение в OpenCL:
Хорошие статьи по основам программирования (отдельный интерес вызывает область применения):
http://www.mql5.com/ru/articles/405
http://www.mql5.com/ru/articles/407
Вебинары по OpenCL:
Курс на Udacity по программированию CUDA:
Выполнение ядра на нескольких GPU:
Причем можно пойти по пути упрощения и задействовать один из специальных планировщиков:
http://www.ida.liu.se/
CUDA – grid, threads, blocks- раскладываем все по полочкам
доступные в сети ресурсы по CUDA
UPDATE 28.06.2013
Враперы для взаимодействия с ОпенСЛ:
JOCL – Java bindings for OpenCL (JOCL)
PyOpenCL – для python
aparapi – полноценная библиотека для жавы
Интересные статью по OpenCL – тут.
доступные материалы курсов по параллельным вычислениям:
Простой компьютерный блог для души)
Core 0 Core 1 в SpeedFan — что это такое?
 Приветствую друзья! Сегодня у нас пойдет речь об программе SpeedFan, которая позволяет узнать температуру процессора, а точнее каждого ядра. Но если пользователь — начинающий, тогда могут возникнуть трудности — показателей много, а что они означают? Я постараюсь помочь с этим вопросом))
Приветствую друзья! Сегодня у нас пойдет речь об программе SpeedFan, которая позволяет узнать температуру процессора, а точнее каждого ядра. Но если пользователь — начинающий, тогда могут возникнуть трудности — показателей много, а что они означают? Я постараюсь помочь с этим вопросом))
Разбираемся
Температура процессора — важна, в том плане, что за ней нужно следить. Не часто, но поглядывать желательно. Хотя должен признаться — я этого совсем не делаю. Просто у меня офисный процессор, он по природе не может греться сильно, да и при этом всем у меня массивный радиатор на нем.. и так уже пару лет, только термопасту менял пару раз и то, наверно можно было обойтись))
Нашел скриншот SpeedFan — и тут видим не только Core 0, Core 1.. но 2, 3:
 На самом деле все просто — сколько ядер, столько и будет Core, ибо слово переводится как ядро. Напротив каждого Core — показывается температура. Кстати первая строчка — GPU, означает видеокарта.
На самом деле все просто — сколько ядер, столько и будет Core, ибо слово переводится как ядро. Напротив каждого Core — показывается температура. Кстати первая строчка — GPU, означает видеокарта.
В первом блоке, тот который идет слева — там Fan1, Fan2.. и потом значение в RPM, но что это? Расшифровывается как Rounds Per Minutes и означает количество оборотов в минуту. Делаем вывод:
- Fan1, Fan2 и остальные — показывает как сильно крутится вентилятор, чем выше, тем лучше охлаждает, но и больше шума. Еще есть GPU Fan — тоже самое, только вентилятор видеокарты.
- Core 0, Core 1 и остальные — обозначает ядра, то есть первое, второе и другие. В нашем случае, в проге SpeedFan — показывает напротив температуру.
Внизу также есть GPU Fan — вот честно скажу, не знаю что это, но возможно.. в процентах чтобы ограничить работу вентилятора видеокарты? Просто первое что пришло в голову..
Vcore1, Vcore2..
В самом низу есть еще один блок — там данные Vcore1, Vcore2 и другие. Здесь информация уже для чистых спецов — вольтаж процессора, видеокарты, постоянных питающих напряжений (это я про линии 12 воль, 5 вольт).. Информация малополезна для обычных пользователей, но главное — программное определение — далеко не лучший способ узнать напряжение… Лучше мерять специальным прибором, как он там называется, мультиметр или вольметр, сам точно не знаю)))
- Core 0, Core 1 — ядро, напротив цифры — номер ядра.
- Данные обозначения часто используются в программах, если нужно показать значения по ядрам.





