Старые версии сайтов вебархив
Что такое веб-архив
21 октября 2017 года. Опубликовано в разделах: Азбука терминов. 30445

Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг. Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org . Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
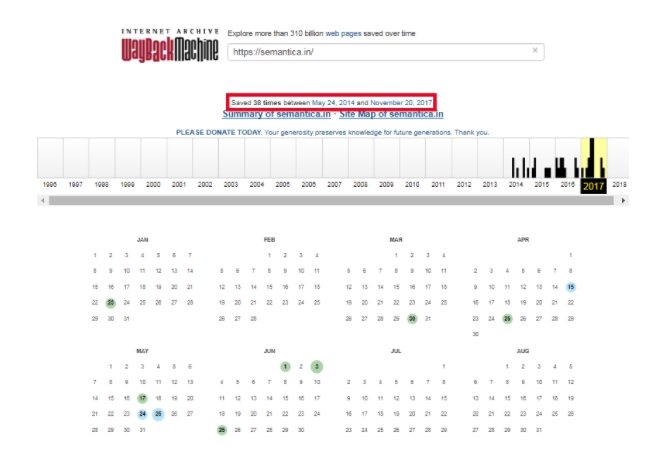 Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
 Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
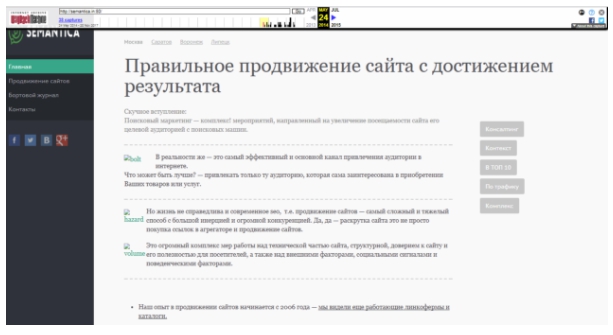 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
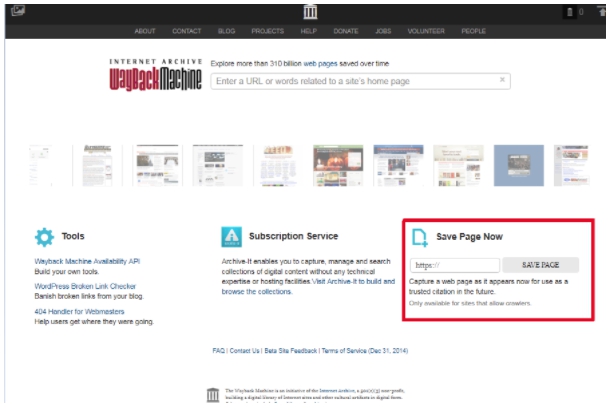 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.

– Только качественный трафик из Яндекса и Google
– Понятная отчетность о работе и о планах работ
– Полная прозрачность работ
Как скачать сайт из вебархива
Обращаю ваше внимание на то, что все операции производятся в операционной системе Ubuntu (Linux). Как все это провернуть на Windows я не знаю. Если хотите все проделать сами, а у вас Windows, то можете поставить VirtualBox, а на него установить ту же Ubuntu. И приготовьтесь к тому, что сайт будет качаться сутки или даже двое. Однажды один сайт у меня скачивался трое суток.
По сути, на текущий момент мы имеем два сервиса с архивом сайтов. Это российский сервис web-archiv.ru и зарубежный archive.org. Я скачивал сайты с обоих сервисов. Только вот в случае с первым, тут не все так просто. Для этого был написан скрипт, который требует доработки, но поскольку мне он более не требуется, соответственно я не стал его дорабатывать. В любом случае его вполне достаточно на то, что бы скачать страницы сайта, но приготовьтесь к ошибкам, поскольку очень велика вероятность появления непредусмотренных особенностей того или иного сайта.
Первым делом я расскажу о том, как скачать сайт с web.archive.org, поскольку это самый простой способ. Вторым способом имеет смысл воспользоваться если по каким-то причинам копия сайта на web.archive.org окажется неполной или её не окажется совсем. Но скорее всего вам вполне хватит первого способа.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:

Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:

Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:

Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.

Долистал я до 23 октября 2017-го и вижу уже другое содержимое:

Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:

А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
- http://web.archive.org/web/ 20180330034350 /http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
- wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
- php get_archive.php “http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F”
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.

Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами.

Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Помощь в скачивании сайта из веб-архива
Если у вас вдруг возникли трудности в том, что бы скачать сайт, можете воспользоваться моими услугами. Буду рад помочь. Для начала заполните и отправьте форму ниже. После этого я с вами свяжусь и мы все обсудим.
Как посмотреть удаленную страницу ВКонтакте
Для многих пользователей, ВК – это хранилище личной информации. Фотографии с памятными моментами, видео с прогулки вашей компании, члены которой уже давно разъехались по разным городам и странам. Вы хранили это в социальной сети, а вашу страницу заблокировали? А может друг удалил свой профиль с ценной информацией. Не огорчайтесь! Не все еще потеряно. Можно использовать веб архив ВКонтакте.
Существует выражение «Все, что попадает в интернет, остается там навсегда». Оно очень близко к истине, ведь даже удаленные страницы в ВК и других соц. сетях можно просмотреть. Для этой цели используется три рабочих инструмента.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.

Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.

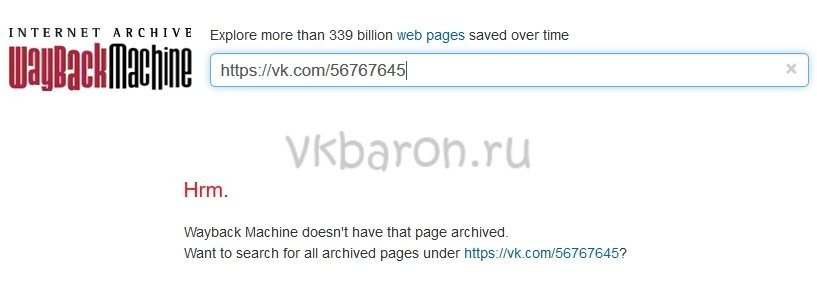
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Справка. Веб-архивы сохраняют всю информацию, которая попадает в интернет без разбора. Видимо по этой причине, доступ к большинству существующих сервисов заблокирован на территории России Роскомнадзором. Чтобы работать с этими сайтами, воспользуйтесь анонимайзером или прокси-сервером.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».

Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Справка. Страница должна быть открыта для индексирования поисковиками в настройках аккаунта ВКонтакте. Если она была скрыта от них, то, соответственно, и сохраненной копии вы найти не сможете.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;

- в этом подменю нажмите «Работать автономно».

Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Важно! После проведенного эксперимента не забудьте отключить автономный режим. Если этого не сделать, браузер не сможет подключиться к интернету.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
Как работать с WebArchive: инструкция
Интернет появился около 37 лет назад, за этот период он все время менялся — что-то совершенствовалось, что-то убиралось, а что-то наоборот появлялось. Сайты постоянно меняли оформление, контент, кнопки и т.д. Для того, чтобы отследить эти изменения в целом или же какой-то конкретной нише, просмотреть сайт конкурентов, который уже не ведется или просмотреть историю интересующего вас сайта/домена — существует Web Archive.
Что такое Web Archive
WebArchive — бесплатный сервис, так называемая машина времени, которая ориентирована исключительно на сайты. Данный сервис хранит архивные данные с историей каждого ресурса, которые включают в себя целые страницы с контентом, заголовками, ссылками, изображениями и т.д.
Отслеживание истории домена необходимо не только в целях интересного времяпровождения, но и позволит вам узнать необходимую для продвижения вашего сайта информацию, такую как:
- Возраст домена, здесь мы уже описывали зачем вам нужны эти данные;
- Тематичность домена — WebArchive позволит вам узнать, не менялась ли тематика данного домена за время его существования, а если менялась, то когда и на какую;
- Увидеть, как сайт выглядел раньше — такая информация будет полезна при покупке б/у доменов;
- Просмотреть удаленный контент на сайте;
- Проверить домен на “чистоту” перед покупкой;
- Восстановить сайт, если до этого вы не сделали резервную копию;
- Отыскать уникальный контент с ресурсов в необходимой для вас нише.
Машина времени сайтов (англ. Wayback Machine) — один из главных проектов archive.org. Данный сервис не является коммерческим и был создан в 1996 году американским программистом Брюстером Кейлом. Архив сайтов имеет четкую цель — искать и собирать копии ресурсов вместе с изображениями, ссылками и контентом для дальнейшей возможности свободного просматривания информации любыми пользователями.
База web archive собиралась на протяжении 20 лет, в ней находится 280 миллиардов страницы, 12 миллионов статей и книг, миллион картинок, а также 100 тысяч программ.
Как пользоваться WebArchive
Сервис крайне прост и удобен в использовании. Приведем пошаговую инструкцию:
1. Заходим на главную страницу сайта — https://web.archive.org/

2. Введите в поиск интересующий вас сайт или же ключевое слово в нужном вам нише и нажмите Enter(подойдет для тех, кто хочет просмотреть все сайты, которые подходят для введенного КС)

3. Появится информация о ресурсе: сколько было сделано резервных копий сайта и с какой даты хранится информация о данном сайте

4. Внизу также будет календарь с отметками по годам, вы можете выбрать интересующий вас год

Проверьте позиции своего сайта прямо сейчас!
После этого на календаре голубым цветом будут выделены отметки, которые указывают на создание копий, вы можете выбрать любую из этих отметок.

5. После выбора отметки вас перебросит на копию сайта в выбранную вами дату. Например, вот так выглядел ресурс Liveinternet 27 марта 2012 года

6. Также вы можете получить общие статистические данные о нужном вам проекте. Для этого под строкой ввода нужно нажать Summary of

7. Еще вы можете ознакомиться с картой сайта, для этого необходимо нажать на кнопку Site Map под строкой ввода сайта

Алгоритм действий прост, а работа с сайтом не займет более 10-ти минут.
Как исключить свой сайт из WebArchive
Если вы по определенным причинам не хотите, чтобы ваш сайт попал в веб архив, то можно прописать запретную директиву в robots.txt вашего сайта, она должна выглядеть так:
После изменений в robots.txt машина времени перестанет делать резервные копии на ваш сайт, а уже имеющиеся сохранения будут удалены. Однако не забывайте, что данные изменения работают только тогда, когда есть доступ к robots.txt вашего сайта и если вы не будете продлевать использование вашего домена, то все изменения будут аннулированы и ваш сайт снова появится на WebArchive для просмотра всех желающих.
Похожие статьи

Руководство по созданию и внедрению микроразметки для вашего сайта
Как использовать микроразметку, чтобы выделить свой сайт в результате поиска и пользователи чаще переходили на него. Самый действенный метод достижения этой цели – работа со структурированными данными. В этой статье мы постараемся разобраться, что же такое структурированные данные и как их можно внедрить на свой сайт.

Микроразметка Schema.org: как использовать для SEO-продвижения
Schema.org — это стандарт семантической разметки (микроразметки) данных на сайтах в сети Интернет. В этой статье мы рассмотрим, что из себя представляет микроразметка, как она позволяет передавать поисковикам основную информацию со страницы, а также в чем её польза для SEO-оптимизации.

12 уникальных SEO-инструментов для эффективных заголовков
Существует огромное количество инструментов, которые помогут вам создать идеальное название страницы. Выбор зависит только от ваших целей и предпочитаемых методов.
Программа для восстановления сайтов из вебархива.
WebArchive Downloader 6.0 – профессиональное программное обеспечение для скачивания сайта и страниц из интернет архива web.archive.org.
Основные преимущества программы:
- Сохраняет все файлы — стили CSS, скрипты, изображения, страницы
- Создает внутреннюю перелинковку страниц сайта
- Возможны два вида внутренних ссылок: файловые и доменные
- Удаляет из текста страниц всю служебную информацию
- Восстанавливать сайт из вебархива на конкретную дату
- Поддерживает три вида кодировки страниц
- Автоматический процесс закачки контента сайта
- Сохраняет полную навигацию по сайту

Применяя WebArchive Downloader 6.0 вы выбираете:
Экономию
денег
Не нужно платить каждый раз за скачивание сайта из web архива. Достаточно один раз просто купить программу.
Автоматизацию
процесса
WebArchive Downloader 6.0 автоматизирует процесс сохранения страниц сайта, изображений и прочего контента.
Больше
времени
Ручной метод сохранения страниц из вебархива очень нудный и занимает много времени. WebArchive Downloader делает это пока вы отдыхаете.
Готовый
сайт
Скачанный сайт, при нормальном его качестве, практически сразу можно размещать на хостинг.
Уникальный
контент
Найдите брошенный домен и получите уникальные статьи и материал для своего сайта.